AI native robotics studio
Design Train Deploy
- Visual workflow blocks
- Built-in AI assistant
- Online training and playback
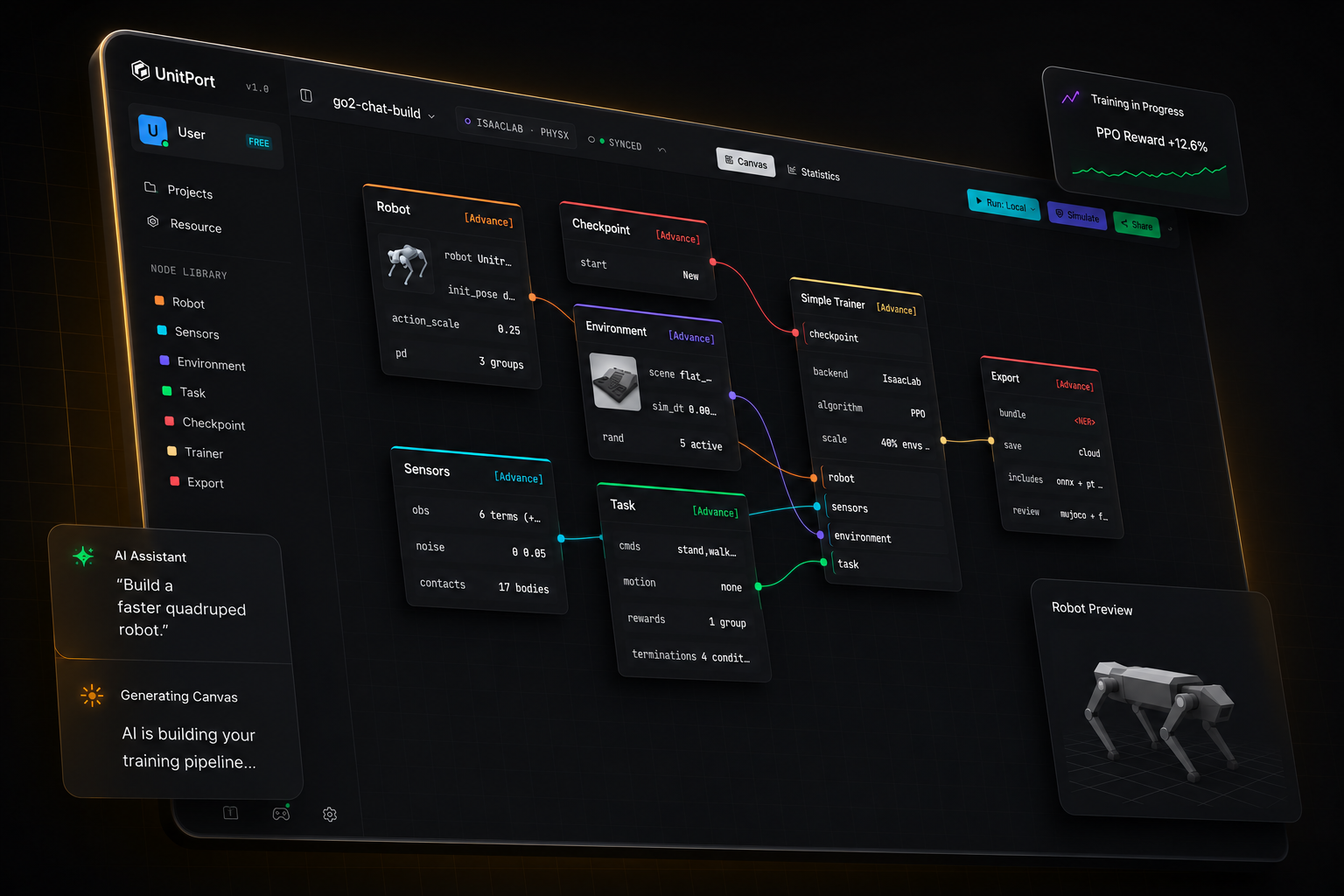
Build with AISay what you want. It builds it.
Visual CanvasDrag blocks. Write no code.
Online Training & SimulationCloud GPU or your own machine.
Robot training has never been this simple
01
Connect
Blocks replace code. Just wire them together.
02
Train
Plug in your own computer, or a cloud GPU.
03
Deploy
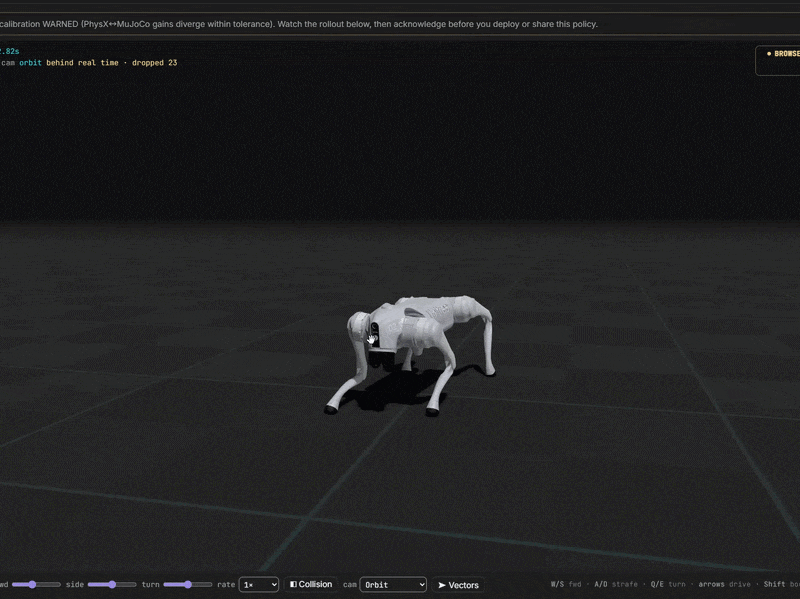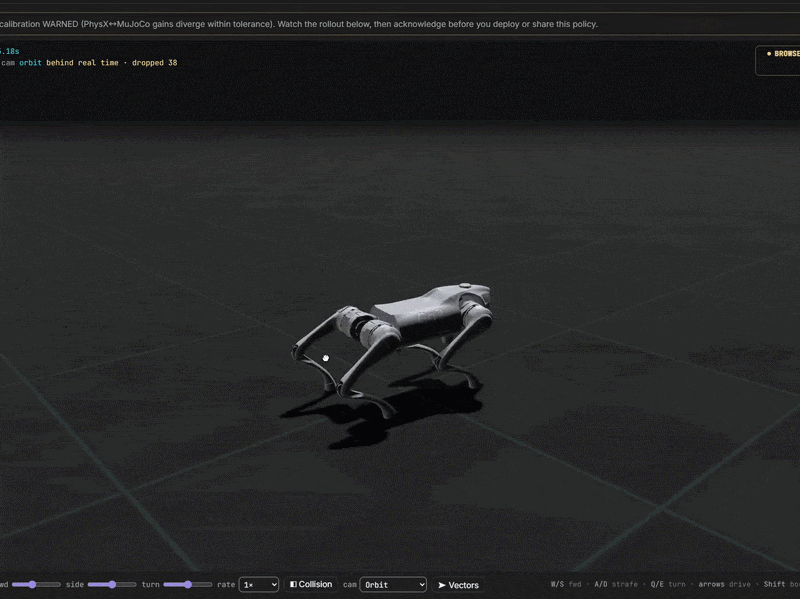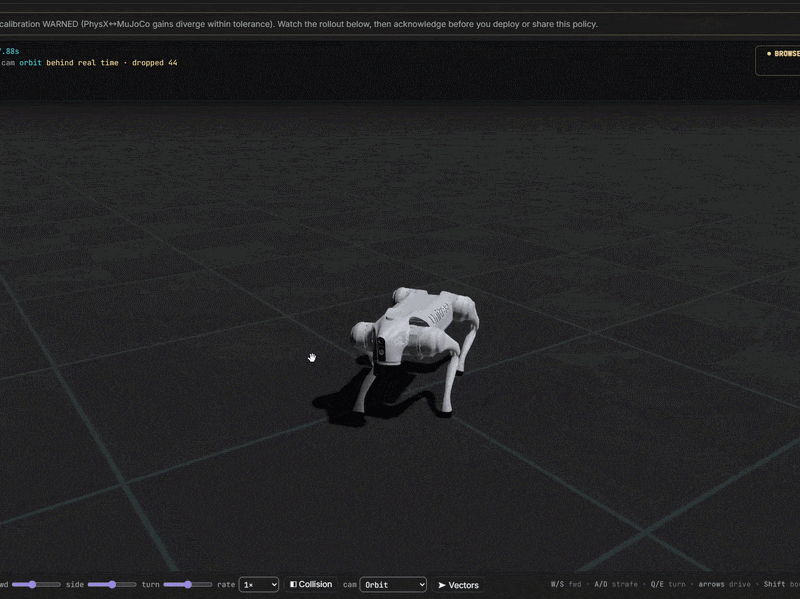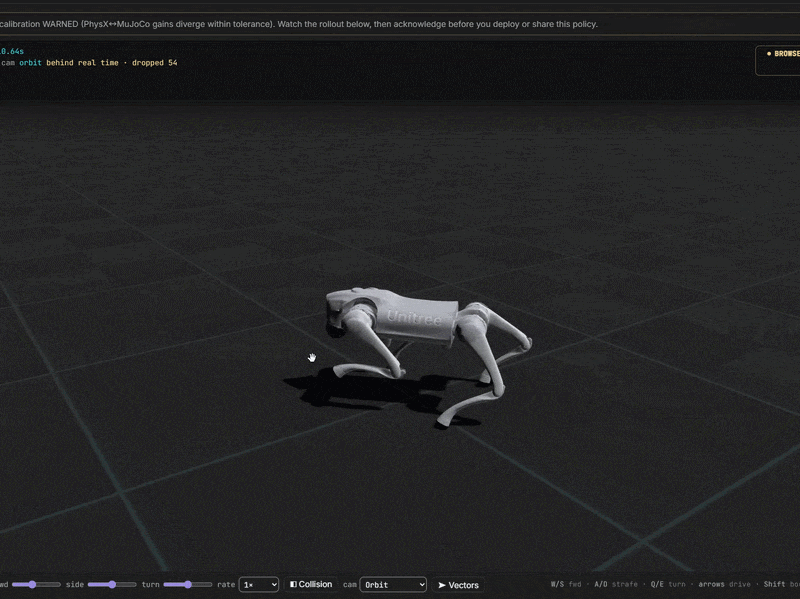
Simulate online, or send it to MuJoCo on your machine.
01 · AI Build
Tell the AI
Tell the AI
It builds the setup
Point it at the AI running on your computer. Or at any API address. Or just use our agent.
Your local AI
Any API address
Or our agent
02 · Visual Canvas
Blocks instead of code
Everything you used to write in code is now a block. Drag it, connect it, done.
No code
Drag and drop
See the whole setup
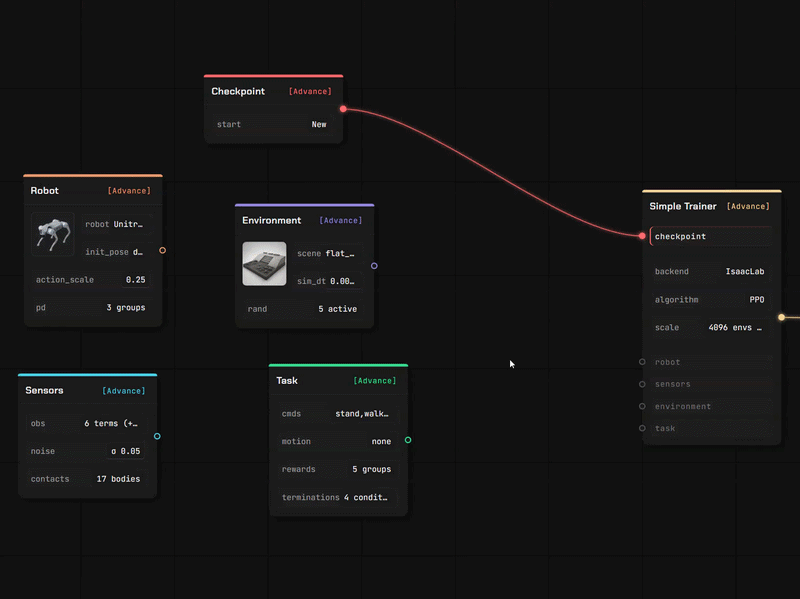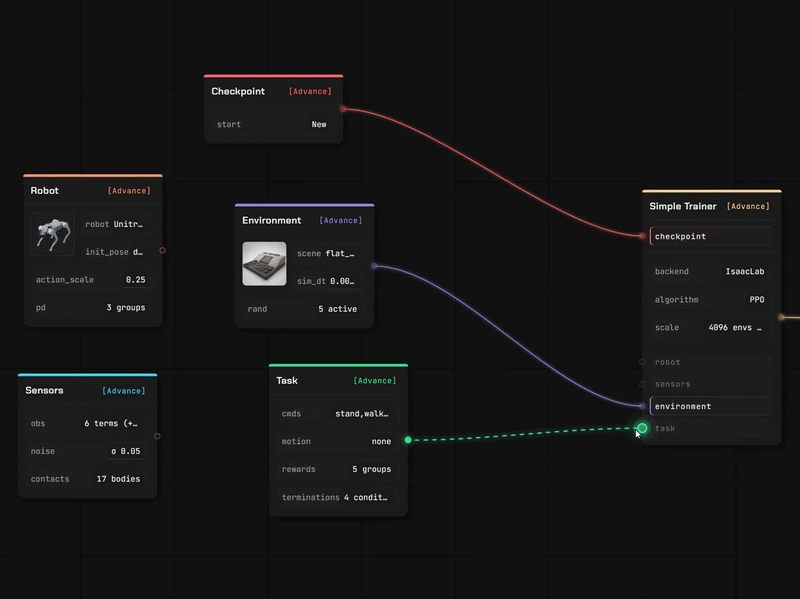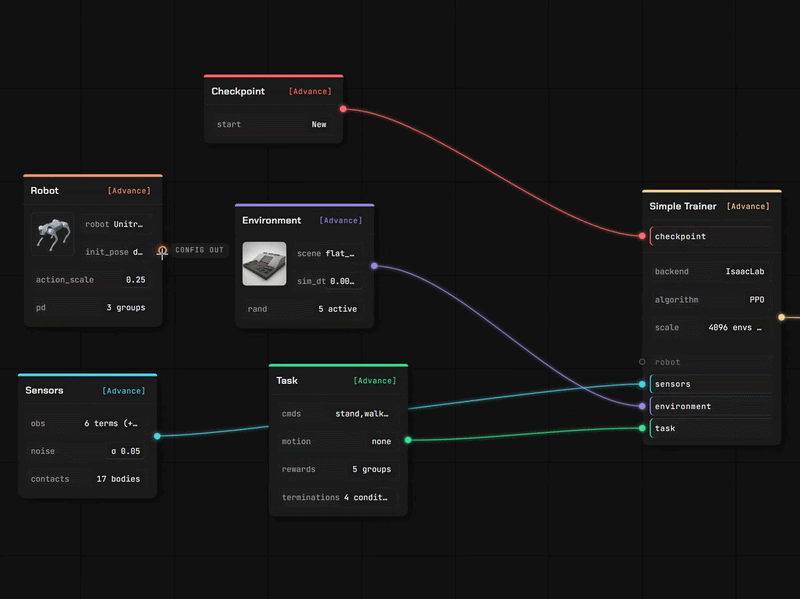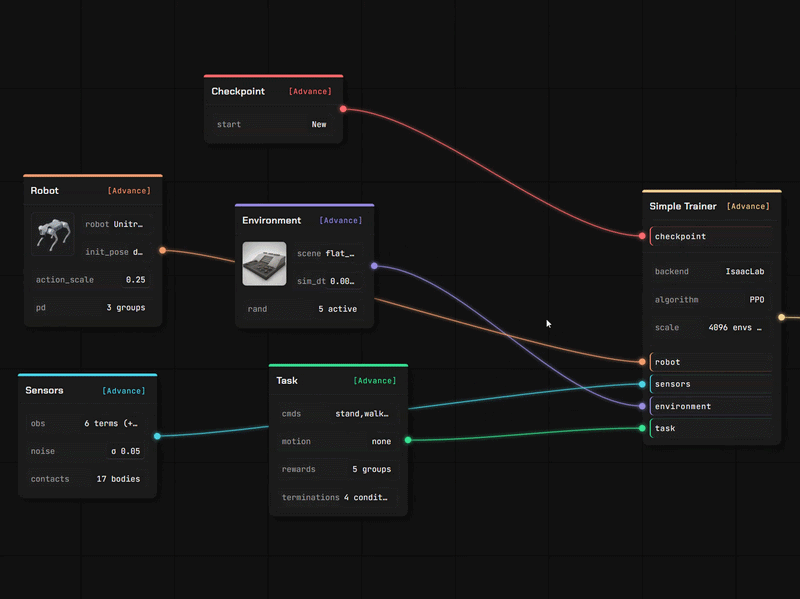
03 · Train & Deploy
Train anywhere
Train anywhere
Simulate online
Use our cloud GPU. Or your own compute center. Or Isaac Lab on your machine.
Our cloud GPU
Your own servers
Local Isaac Lab
From idea to trained robot
You control every cost. Start completely free. No pushy monthly subscriptions.